Pablo’s Data Analytics Portfolio
Data Analytics Projects
Who is Pablo?
I’m a data and people analytics professional with experience transforming complex workforce and business data into actionable insights. My background spans HRIS, BI engineering, and analytics, with hands-on expertise in tools like Power BI, SQL, Python, Workday, and Snowflake. I have been a Data Engineer, a Data Analyst and a Data Consultant which has allowed me to be a pipeline builder, a dashboard designer and most importantly a problem solver. When I’m not working with Data, I’m having fun with Data, feel free to take alook at a couple of my projects below. Currently working on integrating AI with People analytics and building pipelines for AI usage, more to come!
(https://app.powerbi.com/view?r=eyJrIjoiN2IwYjYzYTItOTg1NS00ZGUwLTg1MjYtYzRjZDNjZWY5YTIxIiwidCI6IjYxMWQ0YWIyLWRjNWEtNGZmZC04OTk5LTJjMWY2ZDUwYjE4OCJ9)
new link Link
Tech Stack:
- Power BI: Build self service reports and got data ready for copilot usage
- SQL: Built queries for pipelines and created validationos for proper data ingestion
- Tableau: Ingested, transformed and labeled data from different sources to create dashboards
- Python (Pandas, Seaborn and Scikit - learn): Used pandas to capture data from APIs, SQL servers, Excel files and transformed them into multiple tables for Reporting.
Some accolades I am proud of:
- Built Data Ingestion tool and Analytics structure for a Start up to increase revenue.
- Collaborate with cross-functional teams across the organization to ensure that analytics and reporting are aligned with company priorities
- Serve as a trusted strategic advisor to senior leadership on Data, and provided insights to solve Business Problems.
Project 1: Predictive Analytics: Creating a Recommender system using Singular Value Decomposition
In this exercise, we will get some hands on experience at building a product recommender system using collaborative filtering. In particular, we will implement Singular Value Decomposition. Using python, we would get an algorithm to suggest restaurants to user’s based on their previous visits but also using restaurants that host similar clients. We are going to do so by using ratings as our numerical value attaching 1 restaurant and 1 user to each review. To prevent fake reviews we will only use 1 review per user per restaurant.
We are going to using over 208,166 reviews from users and 10,233 ratings from restaurants using Yelp’s API dataset
Questions this project answers:
- What restaurants are similar/competitive to each other?
- What kind of people go to a specific restaurant?
- Is there a pattern between the restaurant or the client experience? (Are users too kind or is the place actually good)
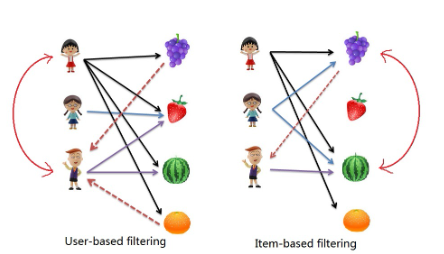
There are 3 types of recommender algorithms (user-based, item-based, model-based) we are going to user the 3rd one)
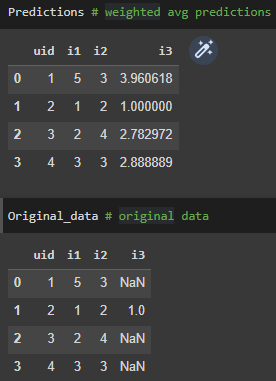
Here is a singular review in rating and how we are going to predict the rating for a restaurant, hence recommending it to a client.
Applications
- Recommender system for items (show new items to potential buyers,movies/series to users, resorts for travelers)
- Uncover segments for a new products (showcase how similar items predict a new trend)
- Able to quantify success across different users (Is our item only successful to one
Project 2: Regression Analysis: Price per stat Model
Why are the bests players in real life not the most expensive players in the game? In this analysis, linear and logistic regression are used to understand the relationship between stats and in game price for all the players. The dataset shows the stats and in-game price for players in FIFA 26.
Context:FIFA is the biggest football videogame in the world, it has its own currency (FIFA points) which can be used to buy players in its own market (FUTM). The market has its own price ranges (max price and min price) which means players are proposed values by the developers of the game, not the market sellers/buyers. Why is the highest rated player not the most expensive player?
Questions this project answers:
- What stats have a higher impact on a players price?
- Is this relationship the same for all positions?
- Is there a clear winner across all of the stats?
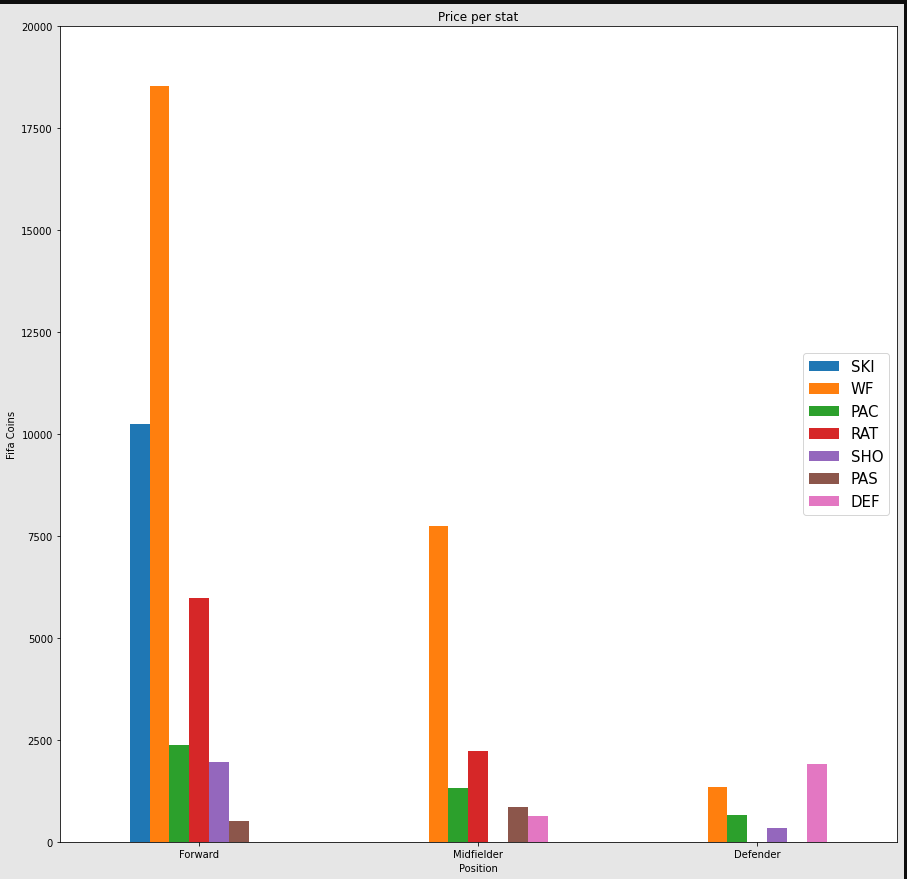 Surprisingly, Weak foot becomes the stat that increases price the most across all positions. This makes sense as being ambidextrous provides an advantage in any position.
Surprisingly, Weak foot becomes the stat that increases price the most across all positions. This makes sense as being ambidextrous provides an advantage in any position.
Applications
- Find relationship between price and stats
- Identify underlying features which could scale profits (invest on a low rated player with high weak foot)
- Uncover less sought options for maximum results
Project 3: Data Science NLP LDA Model: Project Overview
Texts have become one of the most ubiquitous forms of marketing data in the digital economy. Perhaps nowhere is this more salient than in the online reviews domain. In this module, we examined how natural language processing (NLP) techniques can be applied to Honda car reviews. This dataset is available in Kaggle and requires some cleansing and preparation beforehand.
Questions this project answers:
- Are the reviews usually fact or opinion based?
- What are some topics to think when buying a Honda vehicle?
- Are the topics correlating with the ratings?
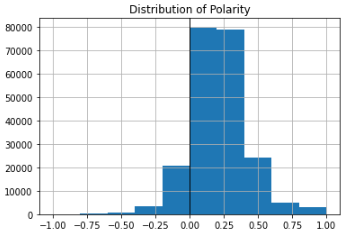
Based on our dataset, most of the reviews show a positive take. (0 = bad, 1 = good)
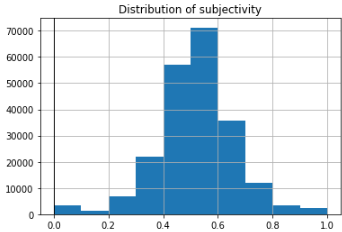
Based on our dataset, most of our reviews fact-based as we can see higher subjectivity. (0 = opinion, 1 = fact)
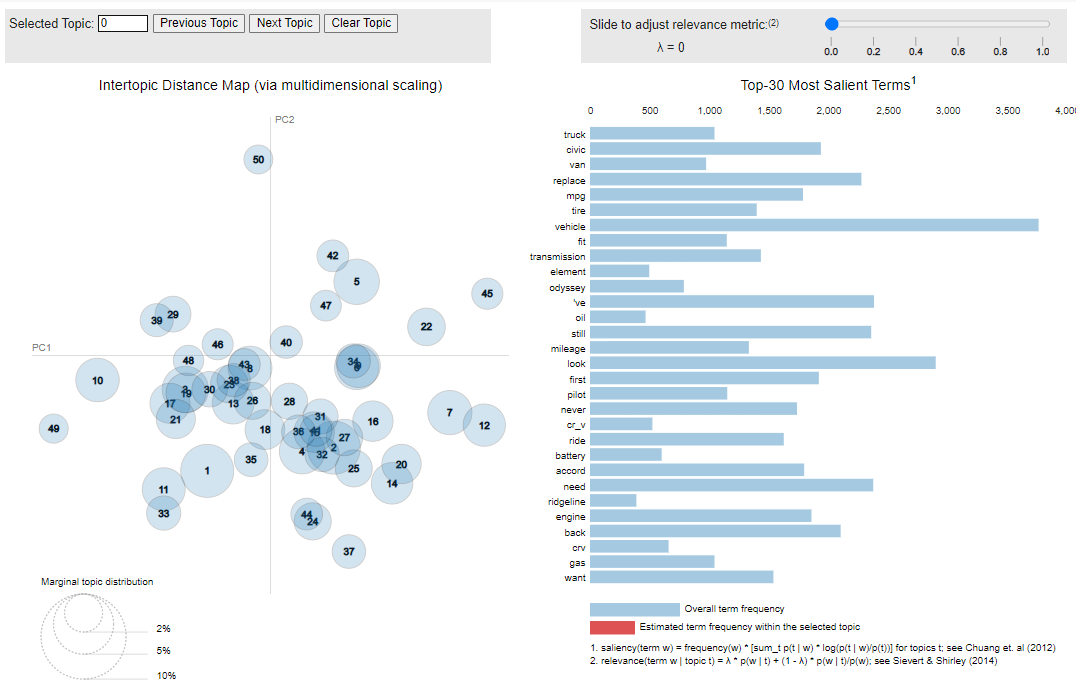
Here is a look at all the topics in our reviews, we can see how the word vehicle is the most used word (we are talking about cars) and how the Honda Odissey seems to be their their most spoken model.
Applications
- Identify commong themes in a dataset
- Analyze how reliable data from reviews can be
- Visualize commong topics for stakeholders
Project 4: Conjoint Analysis: Feature importance in a product
Analysis which provides statistical evidence on which feature has a greater impact in ratings.
Using a dataset from a survey of motorcycles we dissect the importance of features in a product to understand what is best for the client. To do this, we use a hierarchical linear model (HLM) that estimates both the overall fixed effect and the individual level random effect.
Questions this project answers:
- What is the relative importance of a feature in a product?
- Which combination provides a better rating?
- How many different products can be made from a defined set of features?
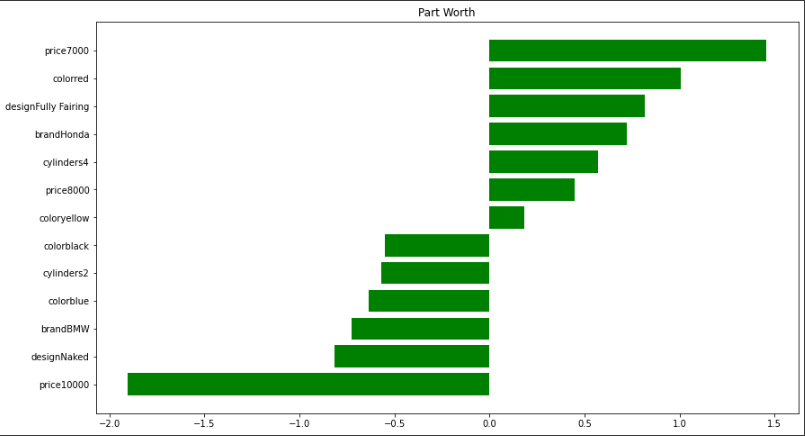
As we can see below, when the price of a car is 7k, it has a positive impact on its rating by 1.5. Moving away is the pricetag of 10k which reduces its rating by 1.9.
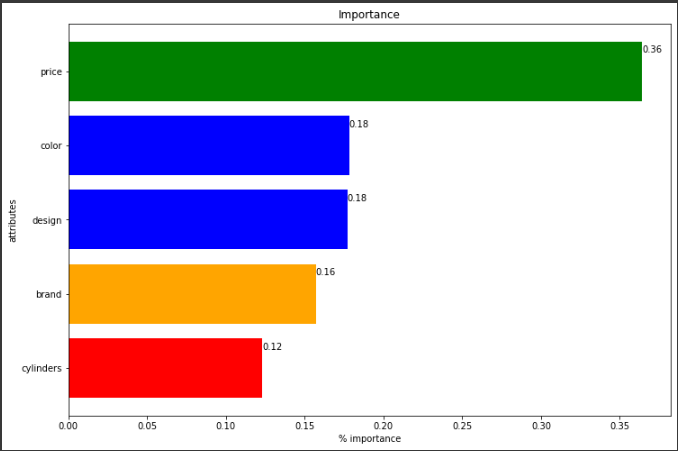
Below is the percentage of relative importance on each feature for a new car. Seems like we are price sensitive.
Applications:
- Understand which importance of features for new products
- Segment populations based on relative of importance
- Find break-even for features in certain products